如何有效地使用Tokenization提升自然语言处理的准
2025-05-08 17:18:57
引言
在快速发展的科技时代,自然语言处理(NLP)已成为人工智能领域的重要分支。Tokenization作为NLP中的一种基础技术,其重要性不言而喻。本文将深入探讨Tokenization的概念、应用及其如何提升自然语言处理的准确性,旨在为研究者与爱好者提供实用的指导和理解。
Tokenization的定义与重要性

Tokenization是将一段文本分割成多个更小的单位,通常称为“tokens”的过程。Tokens可以是单词、短语或符号,具体取决于分析的目的。Tokenization的重要性体现在多个方面:首先,它是文本处理的基础,无论是词袋模型、TF-IDF算法还是深度学习中的文档表示,都是建立在Tokenization的基础上;其次,Tokenization能够有效地帮助算法理解文本的结构与语义,从而提升模型的训练效果和预测能力。
Tokenization的不同方法
Tokenization有多种方法,最常见的包括基于空格的方法和基于规则的方法。基于空格的方法最为简单,将文本按空格分开形成Token。然而,这种方法并无法处理诸如标点符号、缩写词和不同语言的复杂结构。
基于规则的Tokenizer则更加复杂,通常会考虑语言的具体特征。例如,对于英文,可以使用正则表达式来匹配单词与标点符号;而在处理中文时,分词工具如Jieba则能有效识别词语的边界。
Tokenization在自然语言处理中的应用
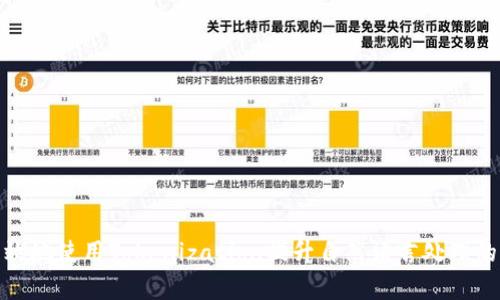
Tokenization在自然语言处理中的应用广泛,涉及情感分析、机器翻译、信息检索等多个领域。在情感分析中,Tokenization帮助模型识别情感词汇并计算其情感倾向;而在机器翻译中,Tokenization确保源语言与目标语言之间的准确对应,通过对Token的处理,可以实现更自然流畅的翻译效果。
提升Tokenization效果的策略
为了提高Tokenization的准确性,可以采取多种策略。首先,结合上下文信息进行Tokenization,而不是单纯依赖静态的方法。其次,利用机器学习方法训练自定义的Tokenizer,使其适合特定领域的文本处理需求。此外,不同语言的Tokenization需要结合该语言的特征,采用针对性的解决方案。
常见问题解答
1. Tokenization对NLP模型的影响是什么?
Tokenization在NLP模型中扮演着至关重要的角色,其影响主要体现在三个方面:数据预处理、模型理解以及结果的生成。首先,Tokenization确保模型能够以标准化的格式接收到输入数据,避免因文本格式不同造成的困扰;其次,优秀的Tokenization能够极大提高模型对文本本质的理解,让模型更好地捕捉到语义信息;最后,Tokenization还影响到结果的生成,良好的Token过程使得生成的文本逻辑更为严谨、自然。
2. 如何选择合适的Tokenizer?
选择合适的Tokenizer需考虑多个因素,包括文本的自然语言特征、分析的目的和数据的量级。如果是英文文本,常用的Tokenizer如NLTK、SpaCy都非常成熟,而对于中文,可以考虑使用结巴分词或HanLP。还需根据项目需求自定义Tokenizer的参数,以适应特定的输入特征与输出需求。
3. 处理噪声文本的Tokenization策略是什么?
在实际应用中,文本数据常常带有噪声,如多余的标点符号、错别字等。这些噪声会对Tokenization产生负面影响。应对策略包括在Tokenization之前进行数据清洗,去掉不必要的符号,统一编码格式;同时可以在Tokenization过程中建立规则,允许Tokenizer识别常见的噪声并进行适当的处理。
4. Tokenization与其它文本处理技术的关系是什么?
Tokenization是文本处理中的基础环节,与其它技术如词性标注、命名实体识别、一致性检验等息息相关。其效果直接影响后续的处理流程,比如词性标注需要依赖于准确的Token分割,而命名实体识别则会在Token识别的基础上进行信息的提取与结构化。因此,增强Tokenization的准确性可对整个文本处理流程产生积极影响。
5. 在机器学习中,如何利用Tokenization来模型?
在机器学习中,Tokenization可以通过几个步骤实现:首先,使用多样化的Tokenization策略以确保不同类型的文本均能被妥善处理;其次,通过交叉验证等方法测试不同Tokenization方法对模型表现的影响,并选择最佳方案;最后,保持Token与特征工程的结合,利用更丰富的语义特征来提升模型性能。
6. Tokenization的未来发展趋势是什么?
随着自然语言处理技术的快速进步,Tokenization的未来发展趋势主要包括几个方向:首先,将会实现更高效的深度学习模型与Tokenization相结合,推动自动化和智能化的发展;其次,针对多语言处理的日益重要,Tokenization将会在跨语言的应用中展现更大的价值;最终,结合人工智能的不断创新,Tokenization还将向更深入的理解与生成能力迈进,在文本处理的各个领域发挥更大的作用。
总结来说,Tokenization在自然语言处理中的作用不可小觑,其不仅是基础的文本分割步骤,更是后续分析和模型构建的基础。通过深入理解Tokenization,人们将能更好地应用NLP技术,为各类项目带来更高的效率和准确性。